Topic Detection and Tracking is not an old research area. It was ‘only’ established in the late 90’s and it didn’t really pick up until a few years later. However, a lot has happened since then and today’s research is almost unrecognizable from back then. In this post, I take a brief look at what Topic Detection and Tracking is and at its history.
What’s Topic Detection and Tracking?
First things first: what is Topic Detection and Tracking or, less formally, event tracking? To understand what it is, start at the end. The final product is a timeline, like the one below.
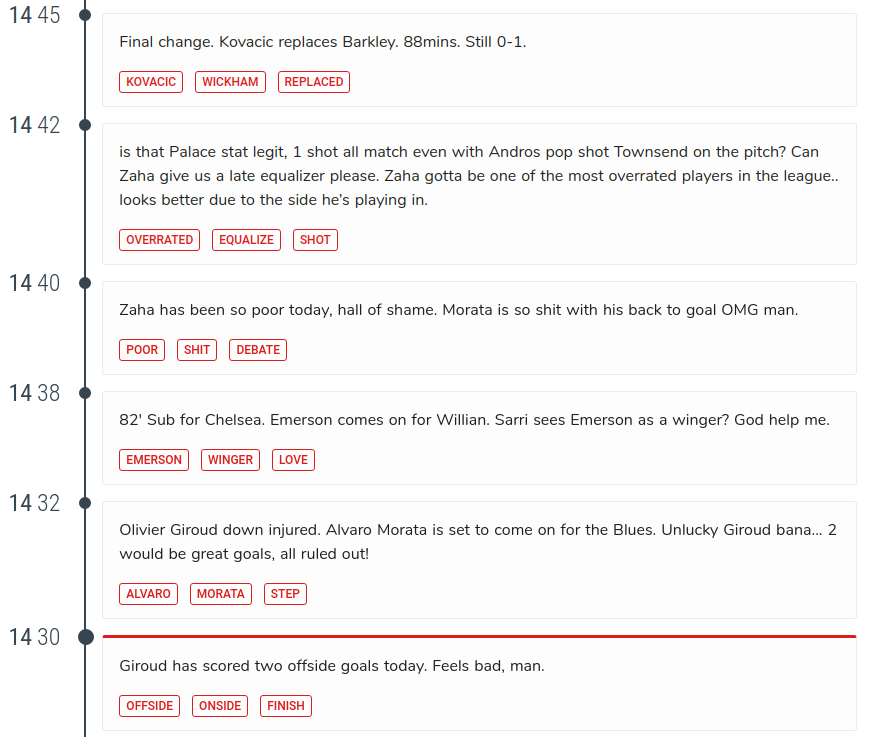 .
.
To build a timeline like that, the system namely performs two tasks, as the name implies: it detects topics, and tracks them until they disappear. A topic is simply a node on the timeline. For example, above we have topics about substitutions, an injury and a goal.
What a topic represents depends a lot on what kind of timeline you are building. For example, the example above is a timeline for a football match. Therefore each topic is something that happened during the match, like a goal or a penalty. If you want to build a timeline of breaking news around the world, each topic is an event, such as an earthquake or a protest.
Now that you understand events, we can go back in time to 1996.
1996: The pilot study of Topic Detection and Tracking
1996 is significant for two reasons: the birth year of yours truly, and the birth year of Topic Detection and Tracking. From September 1996 to October of 1997, DARPA sponsored a pilot study that investigated how successful it would be to find and follow events from news stories.
In 1998, James Allan co-authored a report about the findings. Only it wasn’t just detection and tracking, but three tasks:
- Segmentation splits a stream of text into chunks such that each chunk is one story. In reality, segmentation never really picked up and is no longer common.
- Detection, sometimes called First Story Detection, detects when something new happens.
This can be done in two ways:
- The system waits until it has all the stories and at the end it identifies what happened. This is retrospective Topic Detection and Tracking.
- The system receives one story at a time and decides whether it is a new topic, or a continuation of an older topic. This is on-line Topic Detection and Tracking.
- Tracking decides whether the stories that the system receives belong to a particular topic that we are interested in.
In the beginning, topic tracking was separate from detection and much simpler. For example, imagine that we are interested in the USA’s presidential election. This paper reasons that if we receive a story that mentions the president of the USA, then the story likely belongs to the presidential election. Intuitive, right?
Over time, detection and tracking merged together. Why? Because it made sense. Topic detection and topic tracking overlap a lot: if a story is not a new topic, then it must belong to an older topic.
Then, something happened in 2006 that changed a lot of things, including Topic Detection and Tracking: Twitter was founded.
2006: Topic Detection and Tracking, meet Twitter
Twitter is possibly the best thing that ever happened to Topic Detection and Tracking. Because of Twitter, event tracking suddenly became much more accessible and useful. Unlike bigger social networks, like Facebook, most of the data on Twitter is public and freely-available through its API.
Twitter’s drawback is that professional journalists are no longer the only ones writing news. That means that there is a lot of repetition because when something happens, many users tweet about it. In general, tweets from regular users are also much less formal than a journalistic piece, and have significantly more typos.
However, arguably the worst thing about Twitter aren’t the typos, but that tweets are far shorter than news stories. In the beginning, tweets could be no longer than 140 characters (the limit has since doubled to 280 characters)—that is shorter than this sentence!
Understanding text this short is quite challenging for machines, but it’s not all bad either. Since it takes little time to write a tweet, news travels much faster on Twitter. In fact, Twitter can report breaking news faster than the news outlets. In 2011, Twitter was much smaller than it is today, but news of Osama Bin Laden’s death broke on Twitter, not in the mainstream media.
Just like that, Twitter took over. By 2011, there had been systems to detect earthquakes, create timelines for football matches and more. There has been a lot of research since then, but that doesn’t mean that we’ve ‘solved’ Topic Detection and Tracking.
How Twitter is changing the future
Remember the three tasks of Topic Detection and Tracking? Over time, we went from segmentation, detection and tracking to mostly just detection. Nowadays, detection is no longer sufficient on its own.
For example, Twitter users aren’t journalists, so they don’t only report what is happening. They also give their views and react to what’s happening—with a lot of profanity. Ideally, the timeline shouldn’t include any of that, so the machine needs to be very careful about what to write in the timeline. That problem is summarization.
Twitter also generates a lot of spam and an increasing amount of fake news. All of that is harmful and needs to be filtered out. Therefore detecting and removing spam and noise is a very important research area.
The longer you look, the more problems you find, but stare long enough, and you will also find a lot of opportunities. For instance, with Twitter’s likes and retweets we can measure what content is most popular. Twitter is also a network of users, which means that we can also analyse how people are connected with each other. Spammers, for example, don’t interact with anyone else, so we can use that tidbit to reduce spam.
In short, Twitter brought new challenges and opportunities. That just means we need to overcome the challenges and learn to exploit the opportunities. Twenty-four years after the pilot study, we are still far away from solving the problem, but now we have better tools to solve it.
Reading
If you want to learn more about Topic Detection and Tracking, these papers from this article will get you started:
- Topic Detection and Tracking Pilot Study Final Report: the very first paper about Topic Detection and Tracking.
- Simple Semantics in Topic Detection and Tracking: one of the few approaches that focus on the tracking part.
- Breaking news on twitter: a look at how breaking news spreads on Twitter.
- Earthquake shakes Twitter users: real-time event detection by social sensors: a Topic Detection and Tracking system that detects when and where earthquakes happen.
- Human as Real-Time Sensors of Social and Physical Events: A Case Study of Twitter and Sports Games: the first of many systems that build timelines for sports games.
- Spammer Detection and Fake User Identification on Social Networks: a survey of systems that remove spam and fake users from Twitter.